关于STM32CubeMonitor STM32CubeMonitor主页
CubeMonitor帮助文档
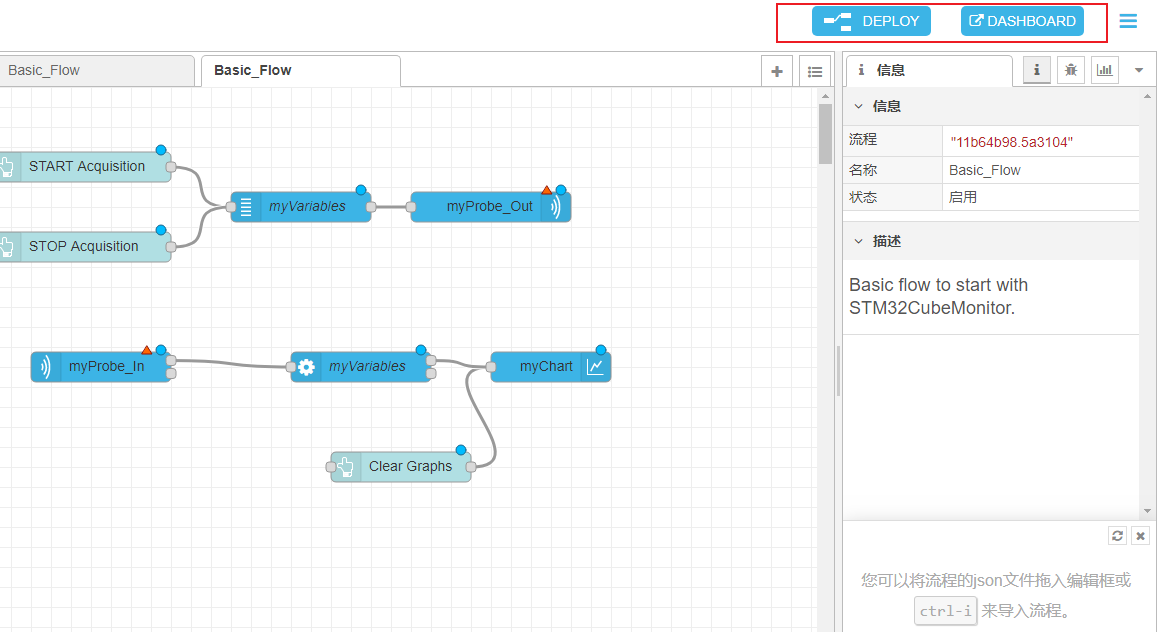
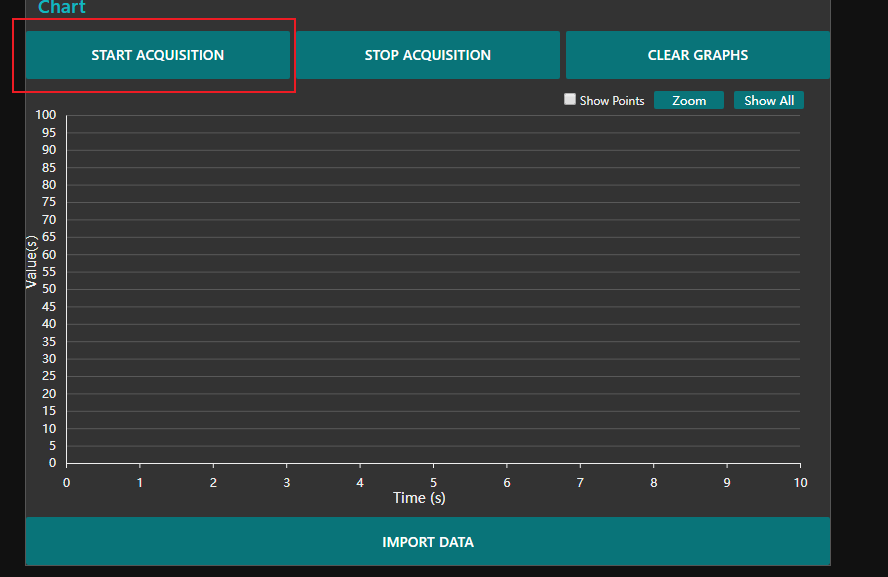
采集数据并显示波形 打开后官方提供了一个Basic Flow给我们使用,通过Deploy后打开Dashboard可以看到我们流程生成的程序
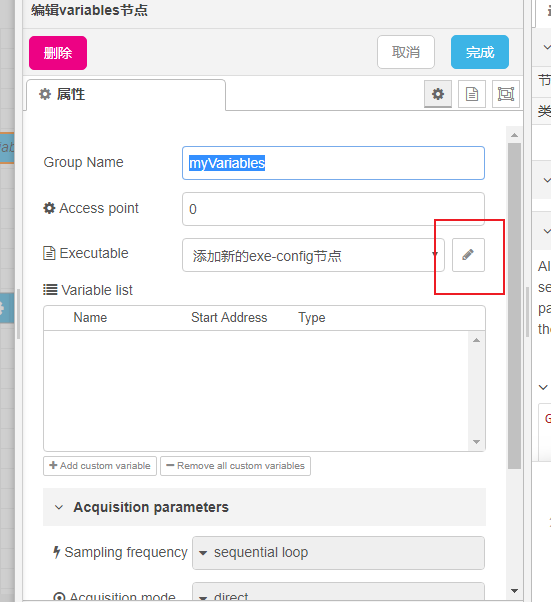
在使用前需要修改myVariables(variable节点)的二进制文件及其变量。双击myVariables,在窗口中选中“添加新的exe-config节点”,点右侧的编辑
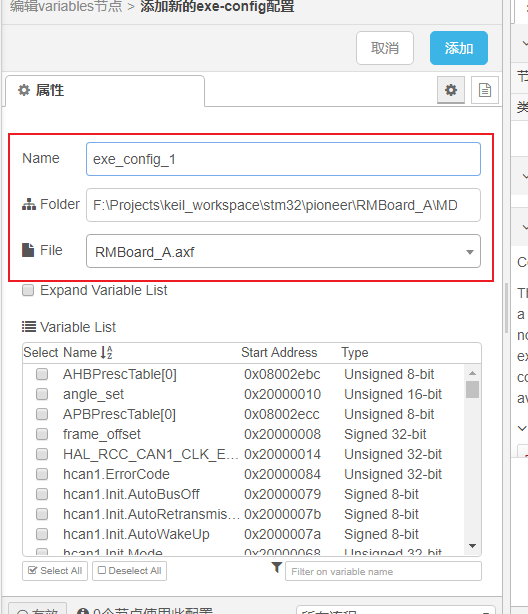
在新的窗口中输入自定的名称,编译后axf文件所在路径以及文件名称,加载二进制文件后会显示其中的全局静态变量,在右下角可以搜索。在想要显示的变量前面打勾即可
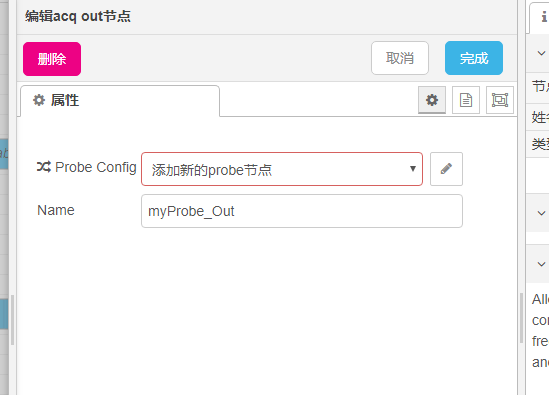
点添加后再点击完成,即完成变量设置。另外还需要指定调试器,在myProbe_Out和myProbe_In(两个Probe节点)上选择对应的调试器,如果没有的话在下拉列表里选“添加新的Probe节点”,选择调试器。
接下来点Deploy再打开Dashboard即可启动程序,按下Start Acquisition可开始采集数据
在线修改变量值
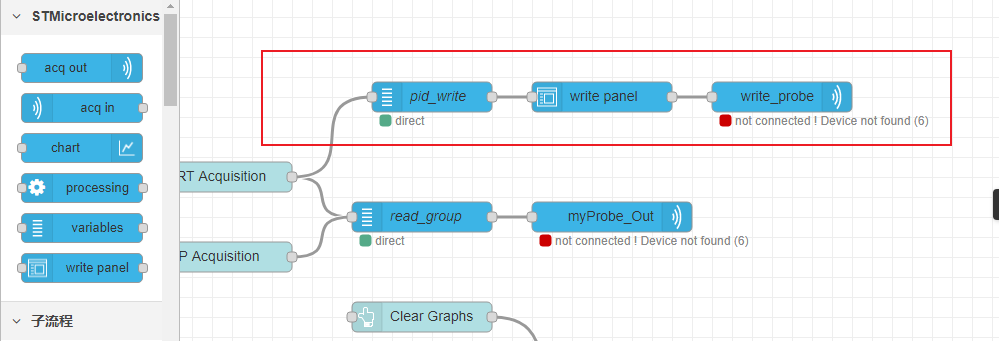
如图,在原来的Basic Flow的基础上添加红色框内方块并连线,variable节点(红框内左一)按照之前读取变量设置的办法,再新建一个变量组用于写入,变量的选择即为想要写入的变量。probe节点(红框内右一)也设置为当前用的调试器。部署之后打开,如下图所示
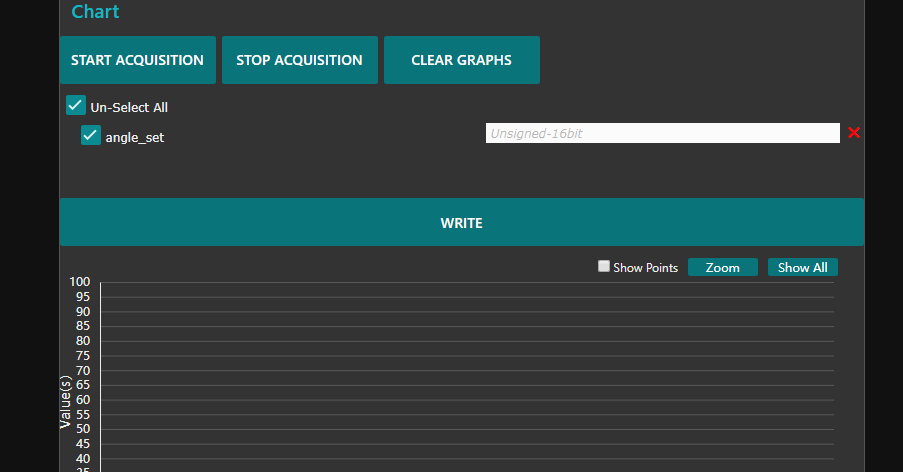
如图,勾选变量并在框内输入值,点击Write即可在线写入变量值
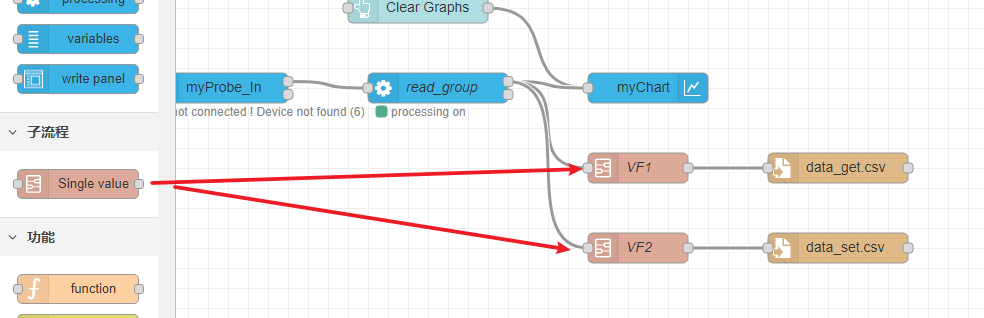
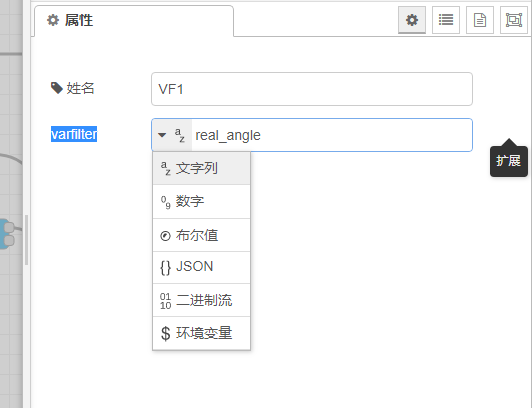
导出数据 方法一:如图,添加两个Single value节点和file节点(由于有两组数据),Single value节点的varfilter设置为文字列,框内写对应的变量名。
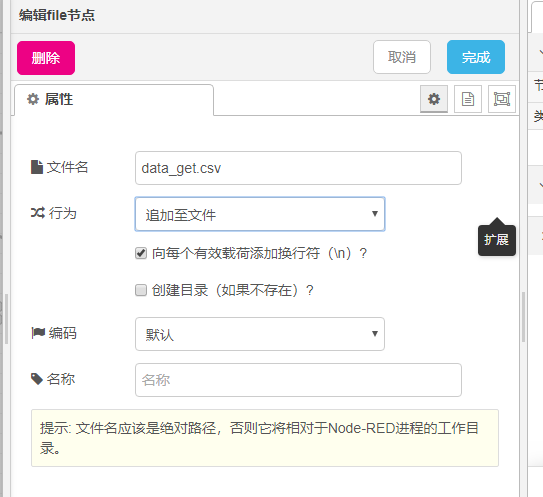
file节点需要写输出的文件名,可以为相对路径或者绝对路径。相对路径的情况下最后文件会保存在CubeMonitor程序的目录下。另外需要修改行为为“追加至文件”
启动后点Start Acquisition,数据就会写入对应的文件中。这个方法虽然能够导出数据,但是从数据数量上来看采样频率明显变低。即使在没有记录对应时间戳的情况下也可以得出数据丢失的结论。为了解决这个问题,需要用方法二。
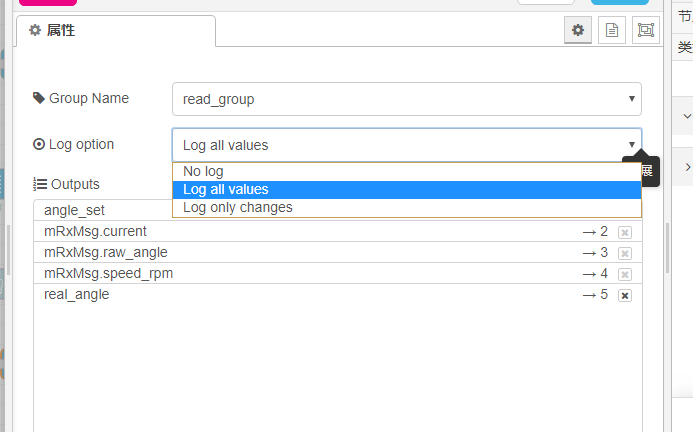
方法二:在输出数据的processing节点的设置中将Log option改为Log all values,启动程序并采集数据。
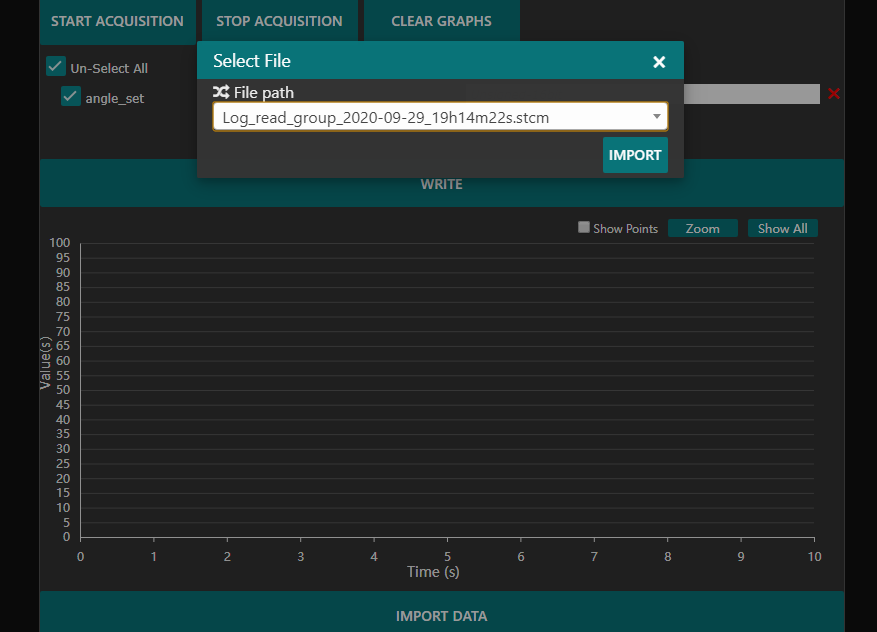
在 %USERPROFILE%/log 路径下会生成.stcm文件,这些为图表的数据来源。在主界面中点下方的Import Data可以导入上一次采集的记录,查看对应的波形
但是这些数据是以json格式储存的,为了后续处理方便要将其转为csv。编写一个Python脚本可实现
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 import json,csvimport sys,osimport globdef stcm2csv (filename ): timestamp=[] dict_data={} f = open (filename,'r' ) for line in f.readlines(): j=json.loads(line) if not dict_data.has_key(j["variablename" ]): dict_data[j["variablename" ]]=[] var_data=j["variabledata" ] for i in range (len (var_data)): if len (timestamp)==0 or var_data[i]["x" ] > timestamp[-1 ]: timestamp.append(var_data[i]["x" ]) dict_data[j["variablename" ]].append(var_data[i]["y" ]) f.close() for i in range (len (dict_data.values())-1 ): assert (len (dict_data.values()[i])==len (dict_data.values()[i+1 ])) csvfilename = filename.replace(".stcm" ,"" )+".csv" f = open (csvfilename,'w' ) writer = csv.writer(f) header = dict_data.keys() header.insert(0 ,"timestamp" ) writer.writerow(header) length = len (timestamp) for i in range (length): single_line=[timestamp[i]] for array in dict_data.values(): single_line.append(array[i]) writer.writerow(single_line) f.close() avg=(timestamp[-1 ]-timestamp[0 ])/len (timestamp) print ("total %d record in file:%s,delta_time=%d,avg_sample_time=%dms" %(len (timestamp),filename,timestamp[-1 ]-timestamp[0 ],avg)) return csvfilename pass def find_step_response (filename,input_col,output_col ): THRESHOLD=30 MAX_SILCE_SIZE=200 step_start=[] export_num=1 if not os.path.exists(".\\step_responses" ): os.mkdir(".\\step_responses" ) f=open (filename,'r' ) csv_data=list (csv.reader(f)) for i in range (1 ,len (csv_data)-1 ): current_val=float (csv_data[i][input_col]) next_val=float (csv_data[i+1 ][input_col]) if (next_val-current_val) > THRESHOLD: f_out=open (".\\step_responses\\" + str (export_num)+"_" +filename,'w' ) writer = csv.writer(f_out) writer.writerow(["input" ,"output" ]) for j in range (1 ,MAX_SILCE_SIZE+1 ): if csv_data[i+j][input_col]==csv_data[i+j+1 ][input_col] or j==0 : writer.writerow([csv_data[i+j][input_col],csv_data[i+j][output_col]]) else : break export_num+=1 f_out.close() step_start.append(i) f.close() return step_start pass if __name__ == '__main__' : INPUT_COL=3 OUTPUT_COL=4 if len (sys.argv)==2 : stcm2csv(str (sys.argv[1 ])) else : all_file_list=glob.glob("*.stcm" ) if len (all_file_list)!=0 : for file in all_file_list: stcm2csv(file)
脚本有两种用法,在参数中指定文件则转换该文件,不指定则将当前目录下的所有stcm文件转换为csv