所谓电路仿真,是指对设计出的电路的实际功能进行模拟。为了最大程度确保电路在实际工程中符合预期,在如今EDA如此发达的时代几乎几乎每个电路设计的流程里面都会用仿真,采用计算机仿真也成了硬件设计的必备技能之一。下面在这里简单介绍一些常用的仿真软件以及使用。由于在RM里硬件的考察主要为超级电容模块的制作,也就是功率硬件的方向,因此这里的仿真将更加侧重于功率电源方向。
SPICE原理仿真
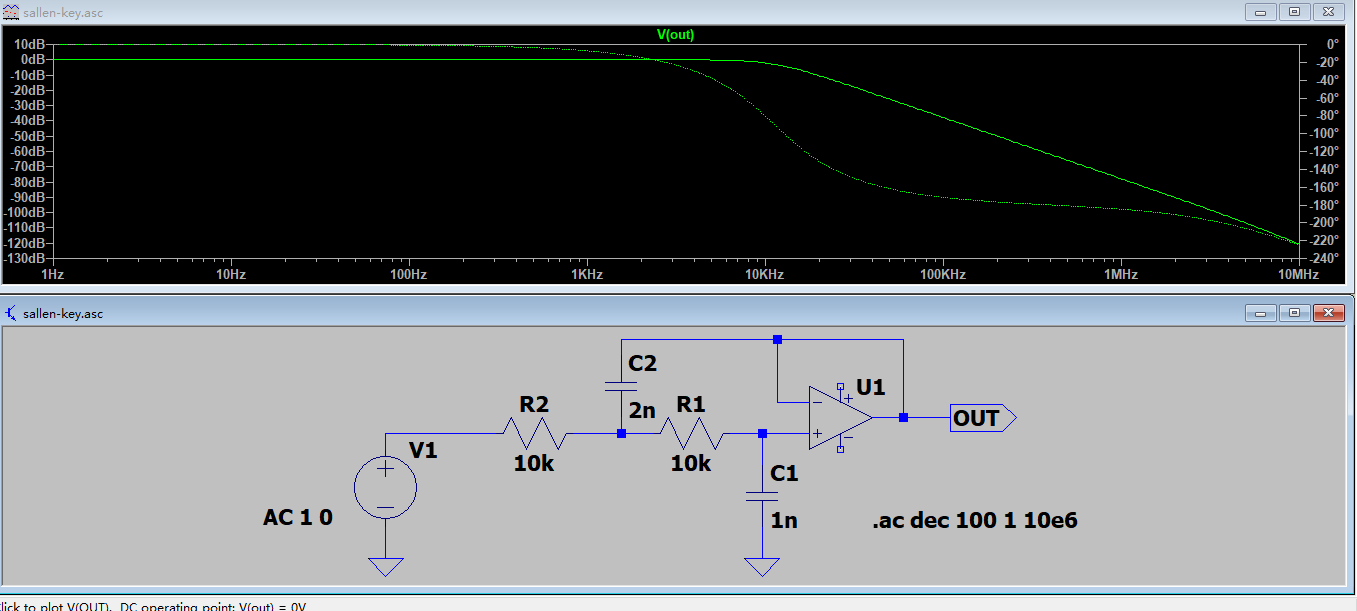
SPICE(Simulation Program with Integrated Circuit Emphasis)为一个早期开源的电路原理仿真的软件,后续衍生出不少的版本。这些版本也由一些半导体厂/电子厂直接开发而来,例如Candence的PSpice,Ti公司版本的PSpice以及用于模拟电路仿真的Tina-Ti,目前我们课堂上用过的NI的Multisim,ADI公司版本的LTSpice,还有开源版本的ngspice(Kicad内置的仿真软件即为这个)
就我个人而言,比较常用的是LTSpice和Tina-Ti,这两个软件可以免费使用,并且LTSpice仿真的速度极快,一般小型的电路10ms的仿真基本上秒出结果。两者均可以进行稳态/瞬态仿真,幅频相频响应仿真,对于目前能接触到的绝大部分电路均可使用。同时SPICE仿真也可以导入厂商给出的IC模型,可参考LTspice 入门教程3 导入仿真模型,对于官方库内不存在的元件也能手动添加参与仿真