以下配置均基于RoboMaster A板
GM6020电机控制
在CubeMX里面配好CAN1, 详细配置按照例程来(其实只要Time Quantum一样即可)
目前已知机器人会在以下几种情况中由于CAN异常出现控制电机不稳定的现象
针对上述问题,在STM32通过CAN控制电机过程中应该:
在用遥控器控制或静止一段长时间后,哨兵6020电机云台自发地抖动。用手拧云台发现控制过程中的力矩时常不均匀,甚至出现一定角度范围内云台电机无力的情况。这种情况同时出现在Pitch和Yaw轴电机上。
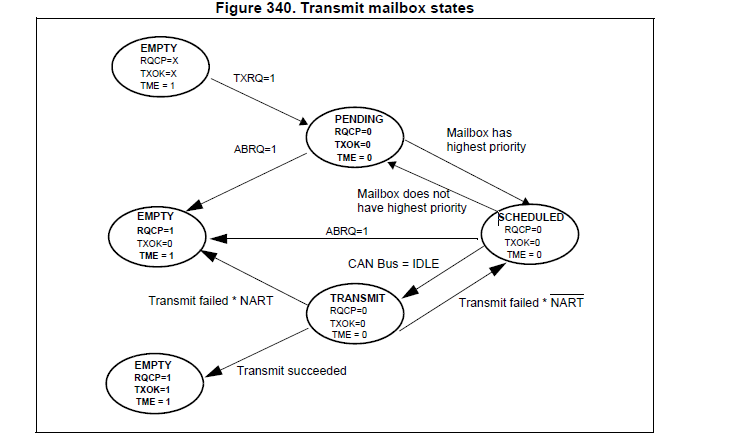
由于CAN总线上可能出现多个设备同时发送数据的情况,而同一时刻CAN总线只能被一个设备占用,因此会出现总线争夺的问题。CAN为了解决这一问题,在总线上有一套规则决定哪一方拥有占用总线的权利,我们称它为总线仲裁。控制电机发送频率越高,CAN总线越容易出现冲突。当CAN的带宽不够用的时候仲裁失败必定有一方出现仲裁失败(CAN一帧为111bit,在1Mbps总线上的带宽约为9帧/毫秒,经过计算目前暂时没有发现有机器人出现这个问题,但是对于较多电机的机器人来说把控制频率改高可能会超过总线带宽,使某些帧总是丢失)。仲裁的结果并不是随机的,CAN发送用的ID越小其优先级越高。当小ID与大ID发送冲突时,仲裁的结果是小ID发送成功,大ID发送失败。而在STM32里面仲裁失败不算发送错误,当出现仲裁失败时ALST位将置1(图1),因此在STM32的错误寄存器里看不到有问题。测试时也去确实发现ALST0出现为1的情况
在哨兵电机ID配置中,云台电机被配置为5和6,发送包的ID为0x2FF刚好比所有电机反馈数据的ID都大(见C620和GM6020文档,电机反馈的ID在0x201~0x20B之间),因此出现仲裁情况时第一个失败的是这一帧。偶尔出现丢失不会引起致命的问题,但是控制方4ms发送一帧,当两者发送频率出现同步时,由于4ms电机反馈周期1ms的整数倍,两者冲突的时间会极长,而每次都是STM32发送方仲裁失败,一段时间之后两者发送时刻错开,STM32又能够在总线空闲时发送,因此能明显发现电机出现无力,但又能恢复的情况。而其他机器人如步兵没有使用以0x2FF为ID的帧做控制,其他的ID如0x1FF和0x200都比电机ID小,因此发送方不可能出现仲裁失败。
SVC:Supervisor Call,指令用于产生一个SVC异常。它是用户模式代码中的主进程,用于创造对特权操作系统代码的调用。SVC是用于呼叫操作系统所提供API的正道。用户程序只需知道传递给操作系统的参数,而不必知道各API函数的地址。
用途:
参考:https://blog.stratifylabs.co/device/2013-10-12-Effective-Use-of-ARM-Cortex-M3-SVCall/
实例:http://www.keil.com/download/files/stm32_svc.zip
在C语言里一种有效组织数据的方式就是结构体,除了储存多种类型的数据外,结构体也是使用一个协议的数据格式最好的办法。这样做还有一个好处就是上位机采用同样的结构体即可通信,在代码层面的移植相当容易。例如
1 | typedef struct{ |
然而有个问题,结构体内部的变量并不是紧密的排在一起,他们中间默认是有空隙的。在上面的代码中sizeof(data_t)的值并不是4+4+1+4,而是在char c后面增加了三个字节的空位。这就是内存对齐的问题,本质的原因是硬件上为了减少访问次数,通常会将变量按照4字节对齐。
通俗一点的解释办法,这个原则就是要求单个变量不能跨4字节(当然双精度对于这个原则不适用,但对于四字节及四字节以下的变量,这个原则却是正确的)。那么有没有变量连续储存的结构体呢?由于内存对齐实际上是编译器的优化,而不是硬件的强制要求,所以我们可以配置编译器让它在以牺牲访问次数的代价来换取这种对齐模式。参照编译器手册,我们可以利用#pragma pack(1)来完成或者在struct前加__PACKED
串口是一种直接接收串行数据的方法,而通常固定数据帧的结构为多个字节,在处理的时候实际上是针对整帧。因此需要通过某种方法将串行数据转换为相当于同一时刻连续出现的数据处理。评定这种转换方法的优劣有以下方面
实际上,在STM32的串口中,我们接收数据通常会采用以下两种方法
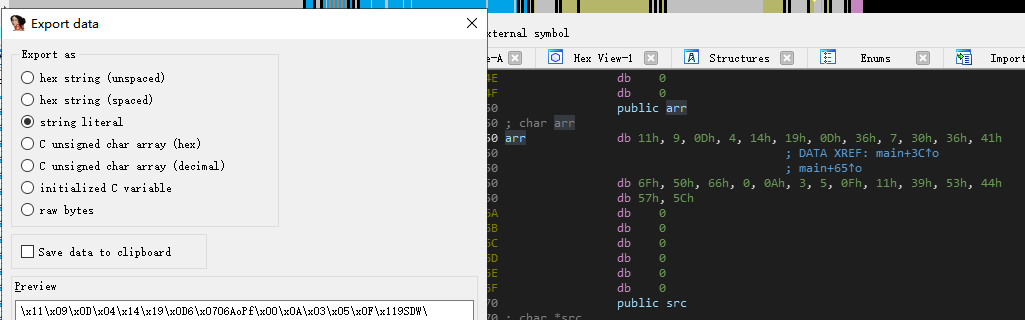
IDA, gdb & pwndbg, checksec, pwntools, LibcSearcher
拿到程序后用checksec看,64位ELF,发现没有主程序canary,NX以及ALSR
1 | [*] '/home/ctf/pwn/pwn1' |